随着Transformer在SOT或VOT的领域中得到广泛的应用,研究者从不同角度探究了基于Transformer的SOT/VOT的方法。众所周知,目前SOT/VOT最常见的改进思路是如何加强模板(template)和搜索区域(search region)特征提取与其二者之间的特征交互。本文将从利用Transformer进行特征交互的角度,对SOT/VOT进行浅谈,并给出一些简单研究和介绍,以飨读者。
由于本文不是严格的学术论文,加之笔者才疏学浅,因此书写规范上略微宽松,存在诸多不严谨或错误之处,请读者谅解和批评。如果能够给读者带来一些帮助,笔者将十分欣慰。
1. 预备知识(Preliminary)
在介绍本文的主要内容之前,由于本博客尚未发布有关SOT/VOT的任何有关信息,因此有必要在第一次介绍SOT相关内容之前将一些必要的前置知识阐述交代。
1.1 SOT/VOT
1.1.1 定义
单目标跟踪(Single Target Object Tracking, SOT)即在跟踪开始的第一帧给定一个任意物体的bounding box,然后能够通过跟踪算法不断更新这个bounding box,以完成目标跟踪。在跟踪过程中,目标可能被遮挡、运动、遮挡、运动、遮挡、运动等,导致目标位置发生变化。
视觉目标跟踪(Visual Object Tracking, VOT)旨在跟踪视频中的一个特定的目标。
这两者的概念在论文中经常被混用,这里本文主要指的是SOT,下文也将简称SOT。
1.1.2 常见名词概念
从数据流的角度,SOT 模型的输入为:
- 模板帧,即Template, 在代码中常常简写为$t$,有时候在论文中也会说成参考帧或参考图像;
- 在线模板,即Online Template, 在代码中常常简写为 $ot$(可选,有些SOT方法不采用在线模板);
- 搜索区域,即Search region, 在代码中常常表示为 $x$, $s$。
SOT模型输出为一系列的目标轨迹,即依时间维度排列的 Bounding box 坐标集合。具体而言,在跟踪的第$i$帧的时刻$t_i$,输入的模板帧的数量和形式各有不同,有些 SOT 算法$^1$输入只有一个 Template,而没有 Online Template。但现在大多数的 SOT 算法$^{2-3}$为了保证跟踪的外观鲁棒性,都会给模型的输入增加一个依照置信度的外观更新参照输入,即 Online Template。
1.1.3 SOT方法范式的发展
在SOT发展的早期,主流方法是基于双分支(two-branch)的孪生网络(the Siamese networks)的方法,该方法将SOT视为一种互相关(cross-correlation)的模板帧和搜索区域之间的相似度匹配问题(the similarity matching problem),这种双分支的方法也深刻影响了基于Transformer的方法。如图1可见,Cui等$^3$认为,流行的SOT模型范式可以看做一个包含三个主要部件的双分支模型。该方法通过将:
- 模板帧和搜索区域送入共享权重的backbone提取图像特征;
- 将二者的特征在融合(integration)模块进行信息交互;
- 最后将输出的响应图送入位置预测头(head)解码成bounding box坐标。

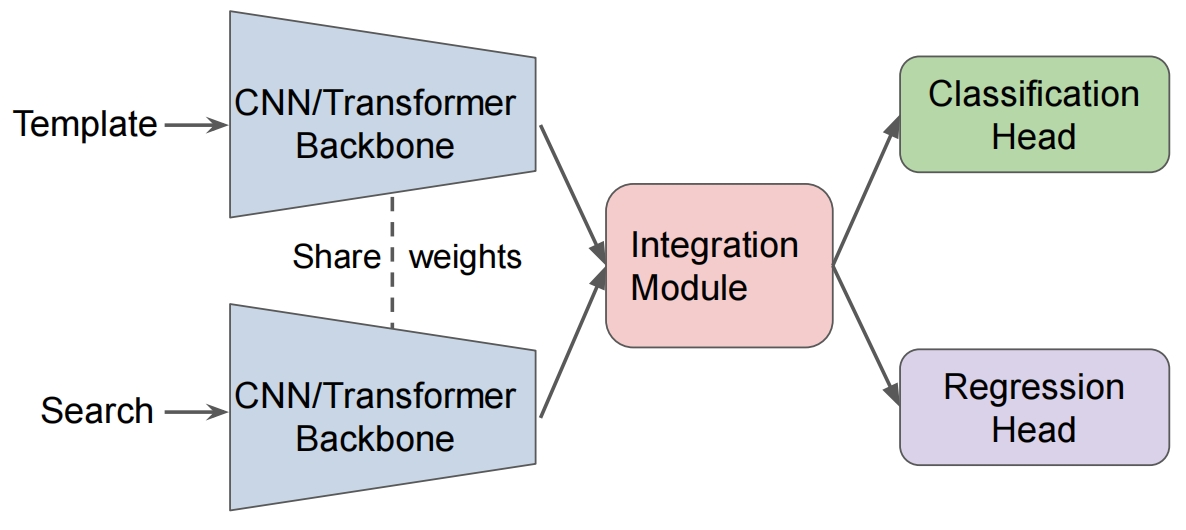
由此可见,基于图1所示的范式,可以把研究对象落实到这三个部分的改进上来。
ViT提出以后,很快就有一些方法将transformer应用到SOT上,如早期的TransT$^4$、STARK$^5$等。图2展示的是STARK的模型框架图,可见该模型很轻易能够区分为图1所展示范式的三个主要部件。
- Backbone:ResNet50/101用于提取$x$, $t$, $ot$特征;
- Integration module: transformer encoder/decoder,其中编码器是transformer blocks,解码器是DETR的解码器,只是把Target Query数量改成1;
- Head: the corner prediction head,将编解码器的特征作简单的点积、哈达玛积和添加shortcut强化特征后reshape送入一个简单FCN预测box,详见请阅论文。
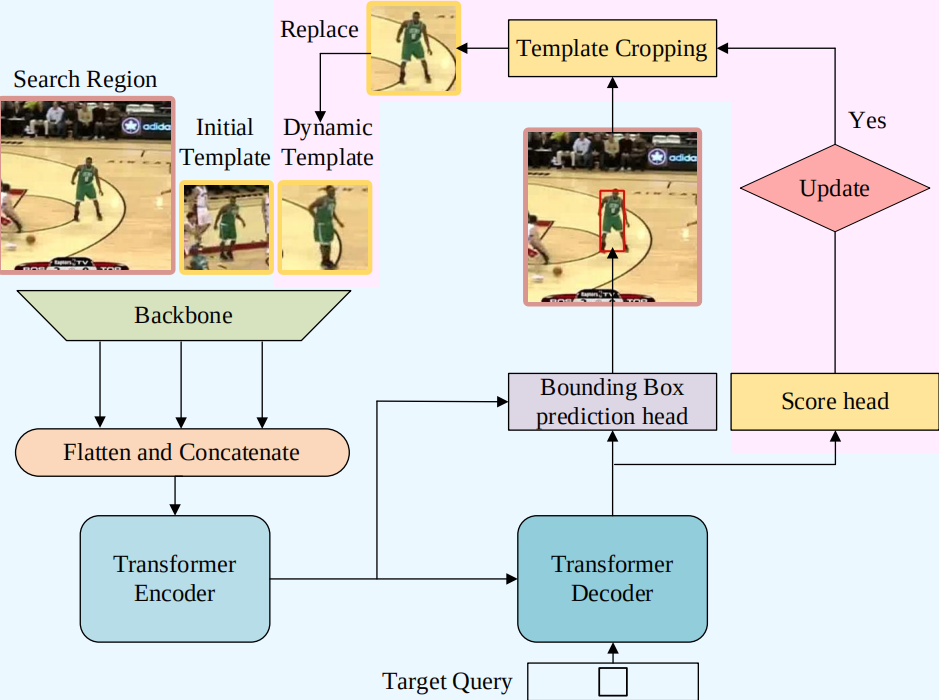
然而,将SOT任务描述成通用与手工设计的task-specific模块之间的组合改进是一个繁琐的过程,如何选择一个通用且有效的backbone,如何精心设计融合模块以及预测头,如何平衡和处理它们之间的模型复杂度和关系,这将带来更让人苦恼的权衡过程。并且解耦以后的各个部分将变得复杂和不利于解释,加上基于注意力的各种transformer变种backbone和基于transformer的融合模块分别处理特征提取和关系建模,以及transformer与生俱来的全局建模能力,使得将特征提取与关系建模解耦成两个模型变得多余。
一个自然的想法就是,能不能利用Transformer,将特征提取与关系建模在同一个backbone中完成,这样不仅能够把模型变得简洁统一,还能够使得特征提取与关系建模在模型的不同层中交互、促进不同水平信号在各层级间传播。
此后,SimTrack$^6$、OSTrack$^1$都是通过将模板帧和搜索区域同时进行patch embedding得到token序列,先后concat起来,送入transformer-base的backbone中,这样就可以很简单地在一个模型中完成了特征提取和关系建模。具体的数学表达将在后文进行介绍。
SimTrack主要对比的Baseline是STARK(为了公平的对比,文章对STARK原模型做了一些调整,如更换原backbone ResNet50到ViT,详见文章$^2, 6$),因此该文章将早期的SOT模型描述成由Backbone、Transformer head、Predictor三个组件组成的一般模型,如图3,这样的模型明显将特征提取和特征交互是解耦在backbone和transformer head中,这种task-specific的设计很明显造成了参数冗余,拖慢了训练和推理速度,并且缺少获取不同环节之间的依赖关系的设计,皆因这种设计思路实质上是将各个模块相对独立地设计和使用。
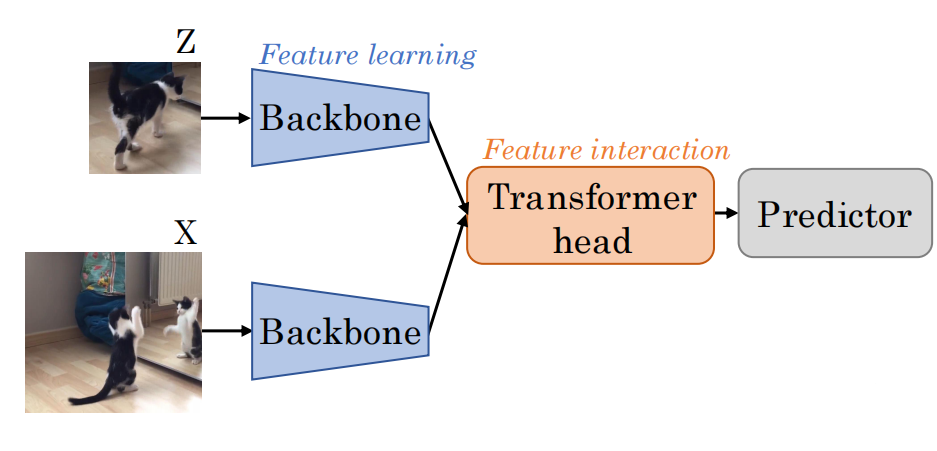
因此,是否能够设计一个通用和统一的模型用于SOT,使得能够克服如上的困难,顺应学界发展的趋势,成为一些研究的研究动机。
SimTrack的思路是设计一种简单的学习框架,通过拼接模板帧和搜索区域的token序列,送入ViT中完成联合学习和交互,节省了一个独立的融合模块,反而获得了更强大的学习能力,如图4所示。
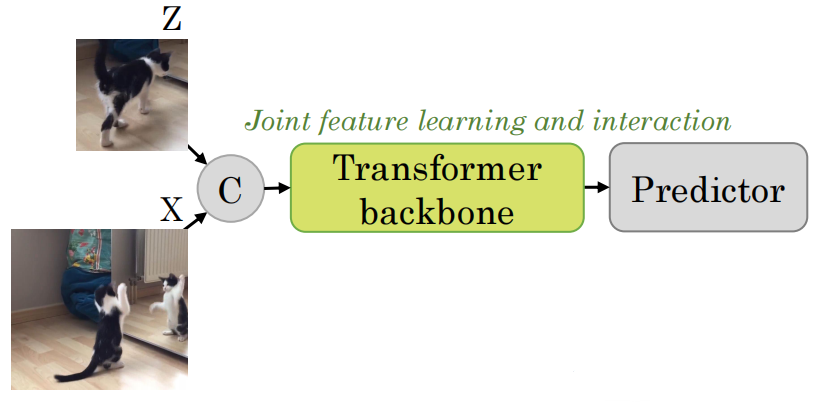
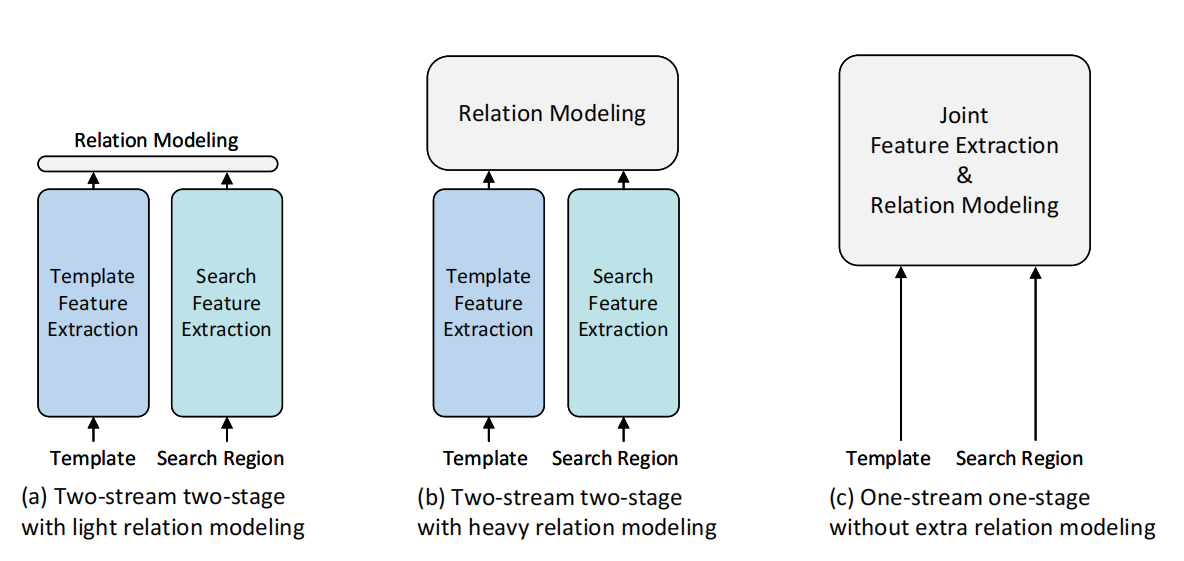
在OSTrack中,作者认为早期的SOT方法实际上是采用一种“分而治之(divide-and-conquer)”的策略,将以前两分支(two-branch)的模型细化描述成一种双流(two-stream)和两阶段(two-stage)的设计,即模板帧与搜索区域独立提取特征(尽管它们在训练和推理共享一个backbone权重)、先特征提取再进行关系建模。
作者坦言,这种将特征提取和关系建模独立运行的操作会降低模型本身的外观鲁棒性,因为这两个部件之间缺乏依赖关系。然而,这种依赖关系在面对跟踪对象外观变化的时候是指导模型正确跟踪目标的重要线索。因此,若能将特征提取和特征交互在同一个环节并行处理并相互指导,势必能够学习到某种隐藏的时空依赖关系。因此,一种能够并行进行特征提取与关系建模的单流(one-stream)跟踪方法被提出,并通过实验证明其克服了双流(two-stream)方法缺乏鲁棒性和参数冗余的困难。
如图5,作者根据上述提到的方法分成具体的三类,其中图5(a-b)皆是双流两阶段的方法,基于孪生网络的方法主要归类于图5(a)所示,TransT$^4$与STARK等transformer-base的早期方法被归类到图5(b)。图5(c)展示的是作者提出的one-stream tracking即OSTrack方法的pipeline,与SimTrack类似地将模板帧和搜索区域经过patch embedding得到的token序列组成图片对(image pair),即先后拼接成一个更长的1-D token序列,在transformer中进行联合特征学习和特征交互的过程。因为没有采用任何mask,所以可以认为是一种自由的信息流动( a free information flow)交互。
SimTrack与OSTrack的设计思想类似,但它们在训练的细节和部分改进上存在一些差异,感兴趣的读者可以自行对比阅读各自文章。
类似地,正如图1最先展示的SOT模型设计范式,Mixformer$^3$正是基于此开始论述自身工作,类似上述的逻辑,Mixformer设计了一种更加紧凑、更加增强特征交互与学习的端到端的网络,根据采取的预训练backbone和设计思想的不同,探索了两种跟踪器,一种是带有渐进向下采样和深度卷积投影的分层跟踪器MixCvT,另一种是基于ViT的普通主干的非分层跟踪器MixViT。它们的主要改进思想是引入混合注意力(mixed attention),根据采取的不同类型的backbone方案(纯ViT与混合卷积-transformer的方法),适应性地手工设计了不同的混合注意力模块MAM(mixed attention module):Wide Mixed Attention Module (W-MAM)、Slimming Mixed Attention Module (S-MAM),如图6所示,展示了MAM的设计细节框图。
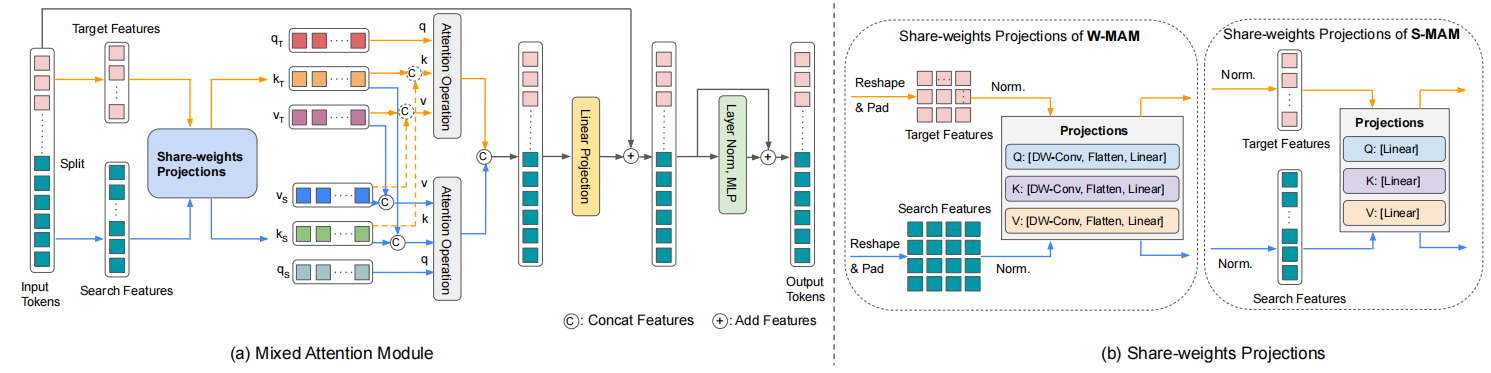
具体细节可以参阅Mixformer文章,但我们应该注意的是,MAM最重要的创新与目的在于,设计增强了模板帧与搜索区域特征的双向交互。这种直接应用于backbone的特征注意力增强,也是当今各种常见改进的主要思路。除了增加shortcut、增强patch embedding特征提取算子、增加更丰富FFN投射、丰富更具有区分性的位置编码和身份编码及偏置表达等tricks上,核心在于模板帧与搜索区域的注意力计算环节,通过element-wise加和或直接concat或引入新的增强算子丰富强化特征再考虑各种增强特征的网络设计,这其中能够改进的途径变得更加多样。
除此之外,Mixformer提供的有关基于MAE的无监督学习的相关研究以及非对称注意力减轻计算负担等研究与巧思也值得研究,但不是本文关注的主题。
1.1.3 小结
尽管不同的文章对于描述一个经典的SOT一般模型的表达形式各不相同,但我们都可以观察到,他们欲表达的SOT的模型范式中必不可少的是如下三个环节:
- 特征提取;
- 关系建模;
- box解码。
早期的算法将三个环节解耦,使用不同的网络组合组成框架先后完成各自的任务。随着学界对Transformer的认识加深,为了追求更全面的特征提取和建模,获取更完整的特征依赖,逐渐将特征提取和关系建模耦合在同一个backbone中,从通用的backbone到精心设计的backbone,背后的潜在逻辑皆是如何增强特征提取以及模板帧与搜索区域之间的特征交互,更好地通过在模板帧中查询搜索区域,得到更具有鲁棒性和区分性的搜索区域响应特征图,得到更强大的跟踪器。
更多早期SOT方法可以参考图的参考资料(出处:https://www.bilibili.com/video/BV1L541127MD ):
2. 公式描述
本小节聚焦于进行特征提取与关系建模的注意力计算中。
基于Transformer的各类注意力机制,其在各项细节上与Vi
T可能都有所改进,但为了不失一般性,下文的流程主要以ViT的计算为例。
在Patch embedding阶段,我们首先将图像
模板帧$\mathbf{Z} \in \mathbb{R}^{H_z \times W_z \times 3}$ 与搜索区域 $\mathbf{X} \in \mathbb{R}^{H_x \times W_x \times 3}$ reshape成一系列的2-D patches。
我们假设划分的Patch大小是$(P, P)$,所以显然划分的的Patch数量$N=HW/P^2$,其中H与W分别代表图像的高、宽。对应到模板帧与搜索区域的Patch数量有$N_z=H_z W_z/P^2$ 与 $N_x=H_x W_x/P^2$。故模板帧与搜索区域原始图像被reshape成$\mathbf{Z_p} \in \mathbb{R}^{N_z \times (P^2 \cdot 3)}$与 $ \mathbf{X_p} \in \mathbb{R}^{N_x \times (P^2 \cdot 3)}$。随后,它们被送入线性投射层,以期获得更丰富的隐表示。特征经过线性层后,其维度转变为线性层定义的输出维度$C$,直接加上位置编码(position embedding)以后分别得到模板帧与搜索区域的token序列,即$t_l \in \mathbb{R}^{N_z \times C}$, $s_l \in \mathbb{R}^{N_x \times C}$。其中$l$代表其处在L层Transformer layer的第$l$层,$l=1, …, L$。
在进行自注意力操作时,每一层的Transformer block都要经过重复的Layer Norm、shortcut、FFN投射等pipeline。如下是以$t^l$为例在第$l$层的特征的前向传播的过程:
$$t’_l=t_l + Attn(LN(t_l)) \tag{1}$$
$$t_{l+1}=t’+FFN(t’) \tag{2}$$
同理$s^l$的自注意力操作同上两式,其中LN代表特征经过Layer Norm作批归一化。
对于注意力机制,众所周知,Transformer中的注意力机制的计算可以表达为:
$$\text{Attn}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right) \cdot V\tag{3}$$
其中$\frac{1}{\sqrt(d)}$为比例因子(the scale factor),$Q, K, V$分别指代注意力机制中的Query、Key、Value。在多头注意力中,输入的token序列要在通道维度切分成$n$个头,为了简单起见,下文忽略多头的情况。则原始的token序列要经过一层投射层以后才可以成为具有丰富空间表达的$Q, K, V$。假设在进行注意力操作之前的特征为$X$,它已经经过patch embedding。那么有:
$$Q = XW_Q\tag{4}$$
其中$W_Q \in \mathbb{R}^{C \times D}$是用于生成Query的投射层的可学习的权重,将维度从$C$投射到$D$。同理,K, V的生成也如上式(4)一般生成:
$$K = XW_K\tag{5}$$
$$V = XW_V\tag{6}$$
其中$W_K \in \mathbb{R}^{C \times D}$,$W_V \in \mathbb{R}^{C \times D}$。
所以,经过上述描述的投射与变换,如果我们用下标 $t$ 和 $s$ 指代Template和Search region,那么Template和Search region图像特征对应的Q, K, V的token序列,其表示符号即$Q_t, K_t, V_t$与$Q_s, K_s, V_s$。
2.1 双流(two-stream)模型的注意力计算
观察图3,很显然双流或者双分支的transformer-base的早期SOT方法的backbone对template和search region特征提取的时候是独立运行的,尽管它们都共享backbone权重。
因为我们要通过注意力的计算阐述单流与双流方法之间的差异,所以我们可以合理假设某一种通用的SOT方法的backbone是ViT。
对于双流的方法,backbone所起到的作用仅是特征提取,因此只能独立进行各自图像特征的自注意力操作。
为了简单起见,下面我们将只讨论在注意力操作上的计算和分析。Template与search region的自注意力操作分别如下:
$$\text{Attn}(Q_t, K_t, V_t) = \text{softmax}\left(\frac{Q_{t}K_{t}^{T}}{\sqrt{d}}\right) \cdot V\tag{7}$$
$$\text{Attn}(Q_s, K_s, V_s) = \text{softmax}\left(\frac{Q_{s}K_{s}^{T}}{\sqrt{d}}\right) \cdot V\tag{8}$$
很显然在这样的独立的特征提取中,模型并不能同时获取到Template和search region之间潜在的依赖关系,这对后续的跟踪是非常不利的。
关于双流模型的关系建模,它们通常是独立于backbone存在的,各种改进与变种层出不穷,因此这里不再过多描述,读者可以详细阅读STARK等工作。
2.2 单流(one-stream)模型的注意力计算
在单流的模型的backbone中,直接在一个阶段内完成了特征提取和关系建模两个步骤。具体而言,最简洁和广泛使用的方法是直接在送入backbone时将模板帧和搜索区域的图像转成patches后在token数量的维度拼接(concat)起来,从输入的1-D token序列的长度的表现而言,即输入的token序列长度增加。
表现在注意力机制的计算上有:
$$ \text{Attn}([Q_t; Q_s], [K_t; K_s], [V_t; V_s]) = softmax \left( \frac{[Q_t; Q_s][K_t; K_s]^T}{\sqrt{d}} \right) \cdot [V_t; V_s]\tag{9}$$
其中,符号”$;$”代表矩阵的元素在垂直方向上分隔,即拼接操作的在tensor形状的表现。如$[Q_t; Q_s]=\begin{bmatrix}Q_t \\ Q_s \\\end{bmatrix}$。
经过矩阵乘法,上式(9)显然可以化为:
$$
softmax (\frac{1}{\sqrt{d}} \cdot
\begin{bmatrix}
Q_t K_t^T & Q_t K_s^T \\
Q_s K_t^T & Q_s K_s^T \\
\end{bmatrix}) \cdot
\begin{bmatrix}
V_t \\
V_s \\
\end{bmatrix}
\tag{10}
$$
可见上式(10)的$\begin{bmatrix}
Q_t K_t^T & Q_t K_s^T \\
Q_s K_t^T & Q_s K_s^T \\
\end{bmatrix}$在对角线上的计算是相当于自注意力的操作,副对角线上的计算是交叉注意力的计算。如子矩阵$Q_t K_t^T$代表的是template特征的token之间的相似度的计算,而$Q_s K_t^T$代表search region对template的交叉注意力的相似度计算。
而我们知道:
- 自注意力代表特征提取;
- 交叉注意力代表关系建模。
因此我们可以仅通过一个简单的拼接实现了在backbone上的特征提取与关系建模之间的耦合操作,并且他们之间是存在自由的特征交互和信息流动的。
2.2.3 复杂度计算
双流模型因将特征提取与关系建模解耦设计,所以难以以一个简单的方法讨论其复杂度。相对而言,观察图5,早期的双流模型的关系建模模型相对轻量而特征提取是相对参数较大,前几年的双流transformer-base的SOT方法加强了关系建模的模型大小。这样解耦的模型想要取得理想的效果必然要使得模型参数愈加庞大和存在参数冗余。
单流模型而言,由于采用2.2.2中讨论的联合特征提取与关系建模的方法,就可以很简单地计算注意力机制涉及到的复杂度。
在SOT的方法中,我们要同时输入Template与search region,它们经过预处理以后裁剪出的固定窗口大小根据模型设计的要求各有不同。因此我们假设问题的规模是token序列的长度,template特征的token长度为$n$,search region为$m$,那么注意力模块的时间复杂度为:
$$O(n^2+2nm+m^2)\tag{11}$$
其中,交叉注意力操作$Q_s K_t^T$与$Q_t K_s^T$的时间复杂度皆为$O(nm)$,自注意力操作$Q_s K_st^T$与$Q_t K_t^T$分别为$O(m^2)$、$O(n^2)$。
因此,对于单流模型,其训练与推理成本对我们在设计模型时选定的超参数$n$, $m$有关,对patch、固定窗口的图像大小敏感。
2.2.4 小结
本节主要通过注意力模块的注意力计算方法探究了双流与单流模型之间在backbone中所起到的作用的异同。
双流与单流模型都进行了自注意力机制的特征提取,但单流模型通过拼接template与search region的token使得特征提取与关系建模可以并行进行,而双流模型只能独立进行特征提取,缺乏template与search region之间的特征交互。但我们也应该注意到,双流模型的计算复杂度与参与计算的token长度有关,因此设计者需要合理平衡性能与效果的关系,选择适合的特征图大小。
参考文献
- Ye B, Chang H, Ma B, et al. Joint feature learning and relation modeling for tracking: A one-stream framework[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 341-357.
- Yan B, Peng H, Fu J, et al. Learning spatio-temporal transformer for visual tracking[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 10448-10457.
- Cui Y, Jiang C, Wang L, et al. Mixformer: End-to-end tracking with iterative mixed attention[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 13608-13618.
- Chen X, Yan B, Zhu J, et al. Transformer tracking[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 8126-8135.
- Yan B, Peng H, Fu J, et al. Learning spatio-temporal transformer for visual tracking[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 10448-10457.
- Chen B, Li P, Bai L, et al. Backbone is all your need: A simplified architecture for visual object tracking[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 375-392.